This post picks up from the previous post on Summer@Brown number theory from 2013.
Now that we’d established ideas about solving the modular equation  , solving the linear diophantine equation
, solving the linear diophantine equation  , and about general modular arithmetic, we began to explore systems of modular equations. That is, we began to look at equations like
, and about general modular arithmetic, we began to explore systems of modular equations. That is, we began to look at equations like
Suppose  satisfies the following three modular equations (rather, the following system of linear congruences):
satisfies the following three modular equations (rather, the following system of linear congruences):



Can we find out what is? This is a clear parallel to solving systems of linear equations, as is usually done in algebra I or II in secondary school. A common way to solve systems of linear equations is to solve for a variable and substitute it into the next equation. We can do something similar here.
From the first equation, we know that  for some
for some  . Substituting this into the second equation, we get that
. Substituting this into the second equation, we get that  , or that
, or that  . So will be the modular inverse of
. So will be the modular inverse of  . A quick calculation (or a slightly less quick Euclidean algorithm in the general case) shows that the inverse is
. A quick calculation (or a slightly less quick Euclidean algorithm in the general case) shows that the inverse is  . Multiplying both sides by yields
. Multiplying both sides by yields  , or rather that
, or rather that  for some
for some  . Back substituting, we see that this means that
. Back substituting, we see that this means that  , or that
, or that  .
.
Now we repeat this work, using the third equation.  , so that
, so that  . Another quick calculation (or Euclidean algorithm) shows that this means
. Another quick calculation (or Euclidean algorithm) shows that this means  , or rather
, or rather  for some
for some  . Putting this back into yields the final answer:
. Putting this back into yields the final answer:


And if you go back and check, you can see that this works. 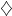
There is another, very slick, method as well. This was a clever solution mentioned in class. The idea is to construct a solution directly. The way we’re going to do this is to set up a sum, where each part only contributes to one of the three modular equations. In particular, note that if we take something like ![7 \cdot 9 \cdot [7\cdot9]_5^{-1}](https://s0.wp.com/latex.php?latex=7+%5Ccdot+9+%5Ccdot+%5B7%5Ccdot9%5D_5%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where this inverse means the modular inverse with respect to
, where this inverse means the modular inverse with respect to  , then this vanishes mod
, then this vanishes mod 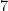 and mod
and mod  , but gives
, but gives  . Similarly
. Similarly ![2\cdot 5 \cdot 9 \cdot [5\cdot9]_7^{-1}](https://s0.wp.com/latex.php?latex=2%5Ccdot+5+%5Ccdot+9+%5Ccdot+%5B5%5Ccdot9%5D_7%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) vanishes mod 5 and mod 9 but leaves the right remainder mod 2, and
vanishes mod 5 and mod 9 but leaves the right remainder mod 2, and ![5 \cdot 7 \cdot [5\cdot 7]_9^{-1}](https://s0.wp.com/latex.php?latex=5+%5Ccdot+7+%5Ccdot+%5B5%5Ccdot+7%5D_9%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) vanishes mod 5 and mod 7, but leaves the right remainder mod 9.
vanishes mod 5 and mod 7, but leaves the right remainder mod 9.
Summing them together yields a solution (Do you see why?). The really nice thing about this algorithm to get the solution is that is parallelizes really well, meaning that you can give different computers separate problems, and then combine the things together to get the final answer. This is going to come up again later in this post.
These are two solutions that follow along the idea of the Chinese Remainder Theorem (CRT), which in general says that as long as the moduli are relative prime, then the system


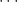

will always have a unique solution  . Note, this is two statements: there is a solution (statement 1), and the statement is unique up to modding by the product of this moduli (statement 2). Proof Sketch: Either of the two methods described above to solve that problem can lead to a proof here. But there is one big step that makes such a proof much easier. Once you’ve shown that the CRT is true for a system of two congruences (effectively meaning you can replace them by one congruence), this means that you can use induction. You can reduce the n+1st case to the nth case using your newfound knowledge of how to combine two equations into one. Then the inductive hypothesis carries out the proof.
. Note, this is two statements: there is a solution (statement 1), and the statement is unique up to modding by the product of this moduli (statement 2). Proof Sketch: Either of the two methods described above to solve that problem can lead to a proof here. But there is one big step that makes such a proof much easier. Once you’ve shown that the CRT is true for a system of two congruences (effectively meaning you can replace them by one congruence), this means that you can use induction. You can reduce the n+1st case to the nth case using your newfound knowledge of how to combine two equations into one. Then the inductive hypothesis carries out the proof.
Note also that it’s pretty easy to go backwards. If I know that  , then I know that will also be the solution to the system
, then I know that will also be the solution to the system


In fact, a higher view of the CRT reveals that the great strength is that considering a number mod a set of relatively prime moduli is the exact same (isomorphic to) considering a number mod the product of the moduli.
The remainder of this post will be about why the CRT is cool and useful.
Application 1: Multiplying Large Numbers
Firstly, the easier application. Suppose you have two really large integers  (by really large, I mean with tens or hundreds of digits at least – for concreteness, say they each have
(by really large, I mean with tens or hundreds of digits at least – for concreteness, say they each have  digits). When a computer computes their product
digits). When a computer computes their product  , it has to perform
, it has to perform 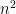 digit multiplications, which can be a whole lot if is big. But a computer can calculate mods of numbers in something like
digit multiplications, which can be a whole lot if is big. But a computer can calculate mods of numbers in something like  time, which is much much much faster. So one way to quickly compute the product of two really large numbers is to use the Chinese Remainder Theorem to represent each of and with a set of much smaller congruences. For example (though we’ll be using small numbers), say we want to multiply
time, which is much much much faster. So one way to quickly compute the product of two really large numbers is to use the Chinese Remainder Theorem to represent each of and with a set of much smaller congruences. For example (though we’ll be using small numbers), say we want to multiply  by
by 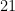 . We might represent by
. We might represent by  and represent by
and represent by  . To find their product, calculate their product in each of the moduli:
. To find their product, calculate their product in each of the moduli:  . We know we can get a solution to the resulting system of congruences using the above algorithm, and the smallest positive solution will be the actual product.
. We know we can get a solution to the resulting system of congruences using the above algorithm, and the smallest positive solution will be the actual product.
This might not feel faster, but for much larger numbers, it really is. As an aside, here’s one way to make it play nice for parallel processing (which vastly makes things faster). After you’ve computed the congruences of and for the different moduli, send the numbers mod 5 to one computer, the numbers mod 7 to another, and the numbers mod 11 to a third (but also send each computer the list of moduli: 5,7,11). Each computer will calculate the product in their modulus and then use the Euclidean algorithm to calculate the inverse of the product of the other two moduli, and multiply these together. Afterwards, the computers resend their data to a central computer, which just adds the result and takes it mod  (to get the smallest positive solution). Since mods are fast and all the multiplication is with smaller integers (no bigger than the largest mod, ever), it all goes faster. And since it’s parallelized, you’re replacing a hard task with a bunch of smaller easier tasks that can all be worked on at the same time. Very powerful stuff!
(to get the smallest positive solution). Since mods are fast and all the multiplication is with smaller integers (no bigger than the largest mod, ever), it all goes faster. And since it’s parallelized, you’re replacing a hard task with a bunch of smaller easier tasks that can all be worked on at the same time. Very powerful stuff!
I have actually never seen someone give the optimal running time that would come from this sort of procedure, though I don’t know why. Perhaps I’ll look into that one day.
Application 2: Secret Sharing in Networks of People
This is really slick. Let’s lay out the situation: I have a secret. I want you, my students, to have access to the secret, but only if at least six of you decide together that you want access. So I give each of you a message, consisting of a number and a modulus. Using the CRT, I can create a scheme where if any six of you decide you want to open the message, then you can pool your six bits together to get the message. Notice, I mean any six of you, instead of a designated set of six. Further, no five people can recover the message without a sixth in a reasonable amount of time. That’s pretty slick, right?
The basic idea is for me to encode my message as a number  (I use P to mean plain-text). Then I choose a set of moduli, one for each of you, but I choose them in such a way that the product of any of them is smaller than , but the product of any
(I use P to mean plain-text). Then I choose a set of moduli, one for each of you, but I choose them in such a way that the product of any of them is smaller than , but the product of any 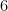 of them is greater than (what this means is that I choose a lot of primes or near-primes right around the same size, all right around the fifth root of ). To each of you, I give you the value of
of them is greater than (what this means is that I choose a lot of primes or near-primes right around the same size, all right around the fifth root of ). To each of you, I give you the value of  and the modulus
and the modulus  , where is your modulus. Since is much bigger than , it would take you a very long time to just happen across the correct multiple that reveals a message (if you ever managed). Now, once six of you get together and put your pieces together, the CRT guarantees a solution. Since the product of your six moduli will be larger than , the smallest solution will be . But if only five of you get together, since the product of your moduli is less than , you don’t recover . In this way, we have our secret sharing network.
, where is your modulus. Since is much bigger than , it would take you a very long time to just happen across the correct multiple that reveals a message (if you ever managed). Now, once six of you get together and put your pieces together, the CRT guarantees a solution. Since the product of your six moduli will be larger than , the smallest solution will be . But if only five of you get together, since the product of your moduli is less than , you don’t recover . In this way, we have our secret sharing network.
To get an idea of the security of this protocol, you might imagine if I gave each of you moduli around the size of a quadrillion. Then missing any single person means there are hundreds of trillions of reasonable multiples of your partial plain-text to check before getting to the correct multiple.
A similar idea, but which doesn’t really use the CRT, is to consider the following problem: suppose two millionaires Alice and Bob (two people of cryptological fame) want to see which of them is richer, but without revealing how much wealth they actually have. This might sound impossible, but indeed it is not! There is a way for them to establish which one is richer but with neither knowing how much money the other has. Similar problems exist for larger parties (more than just 2 people), but none is more famous than the original: Yao’s Millionaire Problem.
Alright – I’ll see you all in class.
Leave a Response »
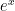 (which is more or less often true). But up to this point in most students’ mathematical development, most mathematics has been clean and perfect; everything has been exact algorithms yielding exact answers for years and years. This is simply not the way of the world.
(which is more or less often true). But up to this point in most students’ mathematical development, most mathematics has been clean and perfect; everything has been exact algorithms yielding exact answers for years and years. This is simply not the way of the world. , we see that
, we see that  is the zero. Similarly, finding roots of quadratic polynomials is very easy, and many of us have memorized the quadratic formula to this end. Thus
is the zero. Similarly, finding roots of quadratic polynomials is very easy, and many of us have memorized the quadratic formula to this end. Thus  has solutions
has solutions  . These are both nice, algorithmic, and exact. But I will guess that the vast majority of those who read this have never seen a “cubic polynomial formula” for finding roots of cubic polynomials (although it does exist, it is horrendously messy – look up
. These are both nice, algorithmic, and exact. But I will guess that the vast majority of those who read this have never seen a “cubic polynomial formula” for finding roots of cubic polynomials (although it does exist, it is horrendously messy – look up 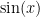 . The most naive approximation that we might do is see that
. The most naive approximation that we might do is see that  , so we might approximate
, so we might approximate  . We know that it’s right at least once, and since
. We know that it’s right at least once, and since 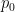 to indicate that this is a degree
to indicate that this is a degree  polynomial, that is, a constant polynomial. Clearly though, this is a terrible approximation, and we can do better.
polynomial, that is, a constant polynomial. Clearly though, this is a terrible approximation, and we can do better.


 , and this is hard to deal with. Let’s draw a right triangle that has
, and this is hard to deal with. Let’s draw a right triangle that has 
 , or that
, or that  , and that
, and that  . If we substitute
. If we substitute  . But this is a substitution, so we need to think about
. But this is a substitution, so we need to think about  too. Here,
too. Here,  .
. or
or  , and got stuck. It’s okay to get stuck, but if you notice that something isn’t working, it’s better to try something else than to stare at the paper for 10 minutes. Other people use
, and got stuck. It’s okay to get stuck, but if you notice that something isn’t working, it’s better to try something else than to stare at the paper for 10 minutes. Other people use  , which is perfectly doable and parallel to what I write below.
, which is perfectly doable and parallel to what I write below. term entirely. But it’s important!.
term entirely. But it’s important!.
 before you give your numerical answer; or you might find the new limits now.
before you give your numerical answer; or you might find the new limits now. to go from
to go from  to
to 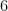 .
. and
and  , then we want a
, then we want a  , so we might use
, so we might use  . Similarly, when
. Similarly, when  , we want
, we want  , like
, like  . Note that these were two arcsine calculations, which we would have to do even if we waited until after we put everything back in terms of
. Note that these were two arcsine calculations, which we would have to do even if we waited until after we put everything back in terms of 
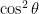 ? We need to make use of the identity
? We need to make use of the identity  . You should know this identity for this midterm. Now we have
. You should know this identity for this midterm. Now we have
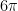 The second integral has antiderivative
The second integral has antiderivative  (Don’t forget the
(Don’t forget the  on bottom!), and we have to evaluate
on bottom!), and we have to evaluate ![{\big[9 \sin 2 \theta \big]_{\pi/6}^{\pi/2}}](https://s0.wp.com/latex.php?latex=%7B%5Cbig%5B9+%5Csin+2+%5Ctheta+%5Cbig%5D_%7B%5Cpi%2F6%7D%5E%7B%5Cpi%2F2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , which gives
, which gives  . You should know the unit circle sufficiently well to evaluate this for your midterm.
. You should know the unit circle sufficiently well to evaluate this for your midterm. . (You don’t need to be able to do that approximation).
. (You don’t need to be able to do that approximation).![\displaystyle 18 \int_{?}^{??}\mathrm{d}\theta + 18 \int_{?}^{??}\cos 2\theta \mathrm{d}\theta = \left[ 18 \theta \right]_?^{??} + \left[ 9 \sin 2 \theta \right]_?^{??}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+18+%5Cint_%7B%3F%7D%5E%7B%3F%3F%7D%5Cmathrm%7Bd%7D%5Ctheta+%2B+18+%5Cint_%7B%3F%7D%5E%7B%3F%3F%7D%5Ccos+2%5Ctheta+%5Cmathrm%7Bd%7D%5Ctheta+%3D+%5Cleft%5B+18+%5Ctheta+%5Cright%5D_%3F%5E%7B%3F%3F%7D+%2B+%5Cleft%5B+9+%5Csin+2+%5Ctheta+%5Cright%5D_%3F%5E%7B%3F%3F%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 . This is how we evaluate the left integral, and we are left with
. This is how we evaluate the left integral, and we are left with ![{[18 \arcsin(x/6)]_3^6}](https://s0.wp.com/latex.php?latex=%7B%5B18+%5Carcsin%28x%2F6%29%5D_3%5E6%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This means we need to know the arcsine of
. This means we need to know the arcsine of  and
and  . These are exactly the same two arcsine computations that I referenced above! Following them again, we get
. These are exactly the same two arcsine computations that I referenced above! Following them again, we get  when
when  is
is  ; and when
; and when  .
. .
. term to deal with. You might recall that
term to deal with. You might recall that  , the so-called double-angle identity.
, the so-called double-angle identity. . Going back to our reference triangle, we know that
. Going back to our reference triangle, we know that  and that
and that  . Putting these together,
. Putting these together,
 , this is
, this is  .
. as something that takes an input
as something that takes an input  . We know functions like
. We know functions like  , which means that if I give in a number
, which means that if I give in a number  , i.e.
, i.e.  . Primary and secondary school overly conditions students to think of functions in terms of a formula or equation. The important thing to remember is that a function is really just something that gives an output when given an input, and if the same input is given later then the function spits the same output out. As an aside, I should mention that the most common problem I’ve seen in my teaching and tutoring is a fundamental misunderstanding of functions and their graphs
. Primary and secondary school overly conditions students to think of functions in terms of a formula or equation. The important thing to remember is that a function is really just something that gives an output when given an input, and if the same input is given later then the function spits the same output out. As an aside, I should mention that the most common problem I’ve seen in my teaching and tutoring is a fundamental misunderstanding of functions and their graphs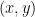 if
if 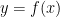 .
.
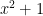 is in blue. The emphasized point appears on the graph because it is of the form
is in blue. The emphasized point appears on the graph because it is of the form  . In particular, this point is
. In particular, this point is 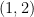 .
.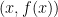 . A large portion of algebra I and II is devoted to being able to draw graphs for a variety of functions. And if you think about it, graphs contain a huge amount of information. Graphing
. A large portion of algebra I and II is devoted to being able to draw graphs for a variety of functions. And if you think about it, graphs contain a huge amount of information. Graphing  involves drawing an upwards-facing parabola, which really represents an infinite number of points. That’s pretty intense, but it’s not what I want to focus on here.
involves drawing an upwards-facing parabola, which really represents an infinite number of points. That’s pretty intense, but it’s not what I want to focus on here. value changes for a specific change in
value changes for a specific change in  and
and 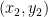 , then its slope will be the vertical change
, then its slope will be the vertical change  divided by the horizontal change
divided by the horizontal change  , or
, or  .
.
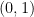 and
and  are shown on the line. The horizontal red line shows the horizontal change. The vertical red line shows the vertical change. The ‘slope’ of the blue line is the length of the vertical red line divided by the length of the horizontal red line.
are shown on the line. The horizontal red line shows the horizontal change. The vertical red line shows the vertical change. The ‘slope’ of the blue line is the length of the vertical red line divided by the length of the horizontal red line. , then the slope from two inputs
, then the slope from two inputs  and
and 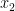 is
is  . As an aside, for those that remember things like the ‘standard equation’
. As an aside, for those that remember things like the ‘standard equation’  or ‘point-slope’
or ‘point-slope’  but who have never thought or been taught where these come from: the claim that lines are the curves of constant slope is saying that for any choice of
but who have never thought or been taught where these come from: the claim that lines are the curves of constant slope is saying that for any choice of  a constant, which I denote by
a constant, which I denote by  for no particularly good reason other than the fact that some textbook author long ago did such a thing. Since we’re allowing ourselves to choose any
for no particularly good reason other than the fact that some textbook author long ago did such a thing. Since we’re allowing ourselves to choose any  , which is what has been so unkindly drilled into students’ heads as the ‘point-slope form.’ This is why lines have a point-slope form, and a reason that it comes up so much is that it comes so naturally from the defining characteristic of a line, i.e. constant slope.
, which is what has been so unkindly drilled into students’ heads as the ‘point-slope form.’ This is why lines have a point-slope form, and a reason that it comes up so much is that it comes so naturally from the defining characteristic of a line, i.e. constant slope.
 is shows in blue. Slope is a measure of how much the function
is shows in blue. Slope is a measure of how much the function  changes when
changes when  and see that the ‘slope,’ or an estimate of how much the function
and see that the ‘slope,’ or an estimate of how much the function 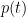 that gave us our position at a time
that gave us our position at a time  , then the slope would give us our velocity (change in position per change in time) at a moment. So without knowing it, we’re familiar with a generalized slope already. Now in our parabola, we don’t expect a constant slope, so we want to associate a ‘slope’ to each input
, then the slope would give us our velocity (change in position per change in time) at a moment. So without knowing it, we’re familiar with a generalized slope already. Now in our parabola, we don’t expect a constant slope, so we want to associate a ‘slope’ to each input  tells us that if we change our input by an amount
tells us that if we change our input by an amount  then our output value will change by
then our output value will change by  .
.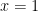 . Let’s get an approximate answer. The slope of the line coming from inputs
. Let’s get an approximate answer. The slope of the line coming from inputs  is a (poor) approximation. In particular, since we’re working with
is a (poor) approximation. In particular, since we’re working with  and
and  . But looking at the graph,
. But looking at the graph,
 and
and  is shown. The line immediately goes above and crosses the parabola, so it seems like this line is rising faster (changing faster) than the parabola. It’s too steep, and the slope is too high to reflect the ‘slope’ of the parabola at the indicated point.
is shown. The line immediately goes above and crosses the parabola, so it seems like this line is rising faster (changing faster) than the parabola. It’s too steep, and the slope is too high to reflect the ‘slope’ of the parabola at the indicated point. . We get that the approximate slope is
. We get that the approximate slope is  . If we were to graph it, this would also feel too large. So we can keep choosing smaller and smaller changes, like using
. If we were to graph it, this would also feel too large. So we can keep choosing smaller and smaller changes, like using  , or
, or  , and so on. This next graphic contains these approximations, with chosen points getting closer and closer to
, and so on. This next graphic contains these approximations, with chosen points getting closer and closer to 
 as our inputs. We get
as our inputs. We get
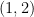 ?
?
 and goes through the point
and goes through the point 
 . In a calculus class, you’ll spend a bit of time making sense of what it means for the approximate slopes to ‘approach’
. In a calculus class, you’ll spend a bit of time making sense of what it means for the approximate slopes to ‘approach’  . If you think about it, we’re saying that we can approximate
. If you think about it, we’re saying that we can approximate  by the line shown in the graph above: this line passes through
by the line shown in the graph above: this line passes through 